This document is a guide to the behaviour of the twisted.internet.defer.Deferred object, and to various
ways you can use them when they are returned by functions.
This document assumes that you are familiar with the basic principle that the Twisted framework is structured around: asynchronous, callback-based programming, where instead of having blocking code in your program or using threads to run blocking code, you have functions that return immediately and then begin a callback chain when data is available.
See these documents for more information:
After reading this document, the reader should expect to be able to deal with most simple APIs in Twisted and Twisted-using code that return Deferreds.
- what sorts of things you can do when you get a Deferred from a function call; and
- how you can write your code to robustly handle errors in Deferred code.
Unless you're already very familiar with asynchronous programming, it's strongly recommended you read the Deferreds section of the Asynchronous programming document to get an idea of why Deferreds exist.
Callbacks
A twisted.internet.defer.Deferred is a promise that
a function will at some point have a result. We can attach callback functions
to a Deferred, and once it gets a result these callbacks will be called. In
addition Deferreds allow the developer to register a callback for an error,
with the default behavior of logging the error. The deferred mechanism
standardizes the application programmer's interface with all sorts of
blocking or delayed operations.
from twisted.internet import reactor, defer def getDummyData(x): """ This function is a dummy which simulates a delayed result and returns a Deferred which will fire with that result. Don't try too hard to understand this. """ d = defer.Deferred() # simulate a delayed result by asking the reactor to fire the # Deferred in 2 seconds time with the result x * 3 reactor.callLater(2, d.callback, x * 3) return d def printData(d): """ Data handling function to be added as a callback: handles the data by printing the result """ print d d = getDummyData(3) d.addCallback(printData) # manually set up the end of the process by asking the reactor to # stop itself in 4 seconds time reactor.callLater(4, reactor.stop) # start up the Twisted reactor (event loop handler) manually reactor.run()
Multiple callbacks
Multiple callbacks can be added to a Deferred. The first callback in the Deferred's callback chain will be called with the result, the second with the result of the first callback, and so on. Why do we need this? Well, consider a Deferred returned by twisted.enterprise.adbapi - the result of a SQL query. A web widget might add a callback that converts this result into HTML, and pass the Deferred onwards, where the callback will be used by twisted to return the result to the HTTP client. The callback chain will be bypassed in case of errors or exceptions.
from twisted.internet import reactor, defer class Getter: def gotResults(self, x): """ The Deferred mechanism provides a mechanism to signal error conditions. In this case, odd numbers are bad. This function demonstrates a more complex way of starting the callback chain by checking for expected results and choosing whether to fire the callback or errback chain """ if x % 2 == 0: self.d.callback(x*3) else: self.d.errback(ValueError("You used an odd number!")) def _toHTML(self, r): """ This function converts r to HTML. It is added to the callback chain by getDummyData in order to demonstrate how a callback passes its own result to the next callback """ return "Result: %s" % r def getDummyData(self, x): """ The Deferred mechanism allows for chained callbacks. In this example, the output of gotResults is first passed through _toHTML on its way to printData. Again this function is a dummy, simulating a delayed result using callLater, rather than using a real asynchronous setup. """ self.d = defer.Deferred() # simulate a delayed result by asking the reactor to schedule # gotResults in 2 seconds time reactor.callLater(2, self.gotResults, x) self.d.addCallback(self._toHTML) return self.d def printData(d): print d def printError(failure): import sys sys.stderr.write(str(failure)) # this series of callbacks and errbacks will print an error message g = Getter() d = g.getDummyData(3) d.addCallback(printData) d.addErrback(printError) # this series of callbacks and errbacks will print "Result: 12" g = Getter() d = g.getDummyData(4) d.addCallback(printData) d.addErrback(printError) reactor.callLater(4, reactor.stop); reactor.run()
Visual Explanation
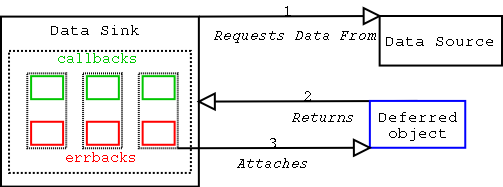
- Requesting method (data sink) requests data, gets Deferred object.
- Requesting method attaches callbacks to Deferred object.
- When the result is ready, give it to the Deferred
object.
.callback(result)if the operation succeeded,.errback(failure)if it failed. Note thatfailureis typically an instance of atwisted.python.failure.Failureinstance. - Deferred object triggers previously-added (call/err)back
with the
resultorfailure. Execution then follows the following rules, going down the chain of callbacks to be processed.- Result of the callback is always passed as the first argument to the next callback, creating a chain of processors.
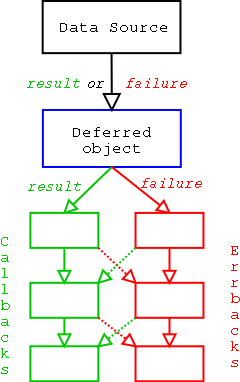
- If a callback raises an exception, switch to errback.
- An unhandled failure gets passed down the line of
errbacks, this creating an asynchronous analog to a
series to a series of
except:statements. - If an errback doesn't raise an exception or return a
twisted.python.failure.Failureinstance, switch to callback.
Errbacks
Deferred's error handling is modeled after Python's exception handling. In the case that no errors occur, all the callbacks run, one after the other, as described above.
If the errback is called instead of the callback (e.g. because a DB query
raised an error), then a twisted.python.failure.Failure is passed into the first
errback (you can add multiple errbacks, just like with callbacks). You can
think of your errbacks as being like except blocks
of ordinary Python code.
Unless you explicitly raise an error in except
block, the Exception is caught and stops
propagating, and normal execution continues. The same thing happens with
errbacks: unless you explicitly return a Failure or (re-)raise an exception, the error stops
propagating, and normal callbacks continue executing from that point (using the
value returned from the errback). If the errback does returns a Failure or raise an exception, then that is passed to the
next errback, and so on.
Note: If an errback doesn't return anything, then it effectively
returns None, meaning that callbacks will continue
to be executed after this errback. This may not be what you expect to happen,
so be careful. Make sure your errbacks return a Failure (probably the one that was passed to it), or a
meaningful return value for the next callback.
Also, twisted.python.failure.Failure instances have
a useful method called trap, allowing you to effectively do the equivalent
of:
try: # code that may throw an exception cookSpamAndEggs() except (SpamException, EggException): # Handle SpamExceptions and EggExceptions ...
You do this by:
def errorHandler(failure): failure.trap(SpamException, EggException) # Handle SpamExceptions and EggExceptions d.addCallback(cookSpamAndEggs) d.addErrback(errorHandler)
If none of arguments passed to failure.trap
match the error encapsulated in that Failure, then
it re-raises the error.
There's another potential gotcha
here. There's a
method twisted.internet.defer.Deferred.addCallbacks
which is similar to, but not exactly the same as, addCallback followed by addErrback. In particular, consider these two cases:
# Case 1 d = getDeferredFromSomewhere() d.addCallback(callback1) # A d.addErrback(errback1) # B d.addCallback(callback2) d.addErrback(errback2) # Case 2 d = getDeferredFromSomewhere() d.addCallbacks(callback1, errback1) # C d.addCallbacks(callback2, errback2)
If an error occurs in callback1, then for Case 1
errback1 will be called with the failure. For Case
2, errback2 will be called. Be careful with your
callbacks and errbacks.
What this means in a practical sense is in Case 1, "A" will
handle a success condition from getDeferredFromSomewhere, and
"B" will handle any errors that occur from either the upstream
source, or that occur in 'A'. In Case 2, "C"'s errback1
will only handle an error condition raised by
getDeferredFromSomewhere, it will not do any handling of
errors raised in callback1.
Unhandled Errors
If a Deferred is garbage-collected with an unhandled error (i.e. it would call the next errback if there was one), then Twisted will write the error's traceback to the log file. This means that you can typically get away with not adding errbacks and still get errors logged. Be careful though; if you keep a reference to the Deferred around, preventing it from being garbage-collected, then you may never see the error (and your callbacks will mysteriously seem to have never been called). If unsure, you should explicitly add an errback after your callbacks, even if all you do is:
# Make sure errors get logged from twisted.python import log d.addErrback(log.err)
Handling either synchronous or asynchronous results
In some applications, there are functions that might be either asynchronous or synchronous. For example, a user authentication function might be able to check in memory whether a user is authenticated, allowing the authentication function to return an immediate result, or it may need to wait on network data, in which case it should return a Deferred to be fired when that data arrives. However, a function that wants to check if a user is authenticated will then need to accept both immediate results and Deferreds.
In this example, the library function authenticateUser uses the
application function isValidUser to authenticate a user:
def authenticateUser(isValidUser, user): if isValidUser(user): print "User is authenticated" else: print "User is not authenticated"
However, it assumes that isValidUser returns immediately,
whereas isValidUser may actually authenticate the user
asynchronously and return a Deferred. It is possible to adapt this
trivial user authentication code to accept either a
synchronous isValidUser or an
asynchronous isValidUser, allowing the library to handle
either type of function. It is, however, also possible to adapt
synchronous functions to return Deferreds. This section describes both
alternatives: handling functions that might be synchronous or
asynchronous in the library function (authenticateUser)
or in the application code.
Handling possible Deferreds in the library code
Here is an example of a synchronous user authentication function that might be
passed to authenticateUser:
def synchronousIsValidUser(user): ''' Return true if user is a valid user, false otherwise ''' return user in ["Alice", "Angus", "Agnes"]
However, here's an asynchronousIsValidUser function that returns
a Deferred:
from twisted.internet import reactor def asynchronousIsValidUser(d, user): d = Deferred() reactor.callLater(2, d.callback, user in ["Alice", "Angus", "Agnes"]) return d
Our original implementation of authenticateUser expected
isValidUser to be synchronous, but now we need to change it to handle both
synchronous and asynchronous implementations of isValidUser. For this, we
use maybeDeferred to
call isValidUser, ensuring that the result of isValidUser is a Deferred,
even if isValidUser is a synchronous function:
from twisted.internet import defer def printResult(result): if result: print "User is authenticated" else: print "User is not authenticated" def authenticateUser(isValidUser, user): d = defer.maybeDeferred(isValidUser, user) d.addCallback(printResult)
Now isValidUser could be either synchronousIsValidUser or
asynchronousIsValidUser.
It is also possible to modify synchronousIsValidUser to return
a Deferred, see Generating Deferreds for more
information.
DeferredList
Sometimes you want to be notified after several different events have all
happened, rather than waiting for each one individually. For example, you may
want to wait for all the connections in a list to close. twisted.internet.defer.DeferredList is the way to do
this.
To create a DeferredList from multiple Deferreds, you simply pass a list of the Deferreds you want it to wait for:
# Creates a DeferredList dl = defer.DeferredList([deferred1, deferred2, deferred3])
You can now treat the DeferredList like an ordinary Deferred; you can call
addCallbacks and so on. The DeferredList will call its callback
when all the deferreds have completed. The callback will be called with a list
of the results of the Deferreds it contains, like so:
def printResult(result): for (success, value) in result: if success: print 'Success:', value else: print 'Failure:', value.getErrorMessage() deferred1 = defer.Deferred() deferred2 = defer.Deferred() deferred3 = defer.Deferred() dl = defer.DeferredList([deferred1, deferred2, deferred3], consumeErrors=True) dl.addCallback(printResult) deferred1.callback('one') deferred2.errback(Exception('bang!')) deferred3.callback('three') # At this point, dl will fire its callback, printing: # Success: one # Failure: bang! # Success: three # (note that defer.SUCCESS == True, and defer.FAILURE == False)
A standard DeferredList will never call errback, but failures in Deferreds
passed to a DeferredList will still errback unless consumeErrors
is passed True. See below for more details about this and other
flags which modify the behavior of DeferredList.
If you want to apply callbacks to the individual Deferreds that go into the DeferredList, you should be careful about when those callbacks are added. The act of adding a Deferred to a DeferredList inserts a callback into that Deferred (when that callback is run, it checks to see if the DeferredList has been completed yet). The important thing to remember is that it is this callback which records the value that goes into the result list handed to the DeferredList's callback.
Therefore, if you add a callback to the Deferred after adding the Deferred to the DeferredList, the value returned by that callback will not be given to the DeferredList's callback. To avoid confusion, we recommend not adding callbacks to a Deferred once it has been used in a DeferredList.
def printResult(result): print result def addTen(result): return result + " ten" # Deferred gets callback before DeferredList is created deferred1 = defer.Deferred() deferred2 = defer.Deferred() deferred1.addCallback(addTen) dl = defer.DeferredList([deferred1, deferred2]) dl.addCallback(printResult) deferred1.callback("one") # fires addTen, checks DeferredList, stores "one ten" deferred2.callback("two") # At this point, dl will fire its callback, printing: # [(1, 'one ten'), (1, 'two')] # Deferred gets callback after DeferredList is created deferred1 = defer.Deferred() deferred2 = defer.Deferred() dl = defer.DeferredList([deferred1, deferred2]) deferred1.addCallback(addTen) # will run *after* DeferredList gets its value dl.addCallback(printResult) deferred1.callback("one") # checks DeferredList, stores "one", fires addTen deferred2.callback("two") # At this point, dl will fire its callback, printing: # [(1, 'one), (1, 'two')]
Other behaviours
DeferredList accepts three keyword arguments that modify its behaviour:
fireOnOneCallback, fireOnOneErrback and
consumeErrors. If fireOnOneCallback is set, the
DeferredList will immediately call its callback as soon as any of its Deferreds
call their callback. Similarly, fireOnOneErrback will call errback
as soon as any of the Deferreds call their errback. Note that DeferredList is
still one-shot, like ordinary Deferreds, so after a callback or errback has been
called the DeferredList will do nothing further (it will just silently ignore
any other results from its Deferreds).
The fireOnOneErrback option is particularly useful when you
want to wait for all the results if everything succeeds, but also want to know
immediately if something fails.
The consumeErrors argument will stop the DeferredList from
propagating any errors along the callback chains of any Deferreds it contains
(usually creating a DeferredList has no effect on the results passed along the
callbacks and errbacks of their Deferreds). Stopping errors at the DeferredList
with this option will prevent Unhandled error in Deferred
warnings from
the Deferreds it contains without needing to add extra errbacks
Class Overview
This is an overview API reference for Deferred from the point of using a Deferred returned by a function. It is not meant to be a substitute for the docstrings in the Deferred class, but can provide guidelines for its use.
There is a parallel overview of functions used by the Deferred's creator in Generating Deferreds.
Basic Callback Functions
addCallbacks(self, callback[, errback, callbackArgs, callbackKeywords, errbackArgs, errbackKeywords])This is the method you will use to interact with Deferred. It adds a pair of callbacks
parallel
to each other (see diagram above) in the list of callbacks made when the Deferred is called back to. The signature of a method added using addCallbacks should bemyMethod(result, *methodArgs, **methodKeywords). If your method is passed in the callback slot, for example, all arguments in the tuplecallbackArgswill be passed as*methodArgsto your method.There are various convenience methods that are derivative of addCallbacks. I will not cover them in detail here, but it is important to know about them in order to create concise code.
addCallback(callback, *callbackArgs, **callbackKeywords)Adds your callback at the next point in the processing chain, while adding an errback that will re-raise its first argument, not affecting further processing in the error case.
Note that, while addCallbacks (plural) requires the arguments to be passed in a tuple, addCallback (singular) takes all its remaining arguments as things to be passed to the callback function. The reason is obvious: addCallbacks (plural) cannot tell whether the arguments are meant for the callback or the errback, so they must be specifically marked by putting them into a tuple. addCallback (singular) knows that everything is destined to go to the callback, so it can use Python's
*
and**
syntax to collect the remaining arguments.addErrback(errback, *errbackArgs, **errbackKeywords)Adds your errback at the next point in the processing chain, while adding a callback that will return its first argument, not affecting further processing in the success case.
addBoth(callbackOrErrback, *callbackOrErrbackArgs, **callbackOrErrbackKeywords)This method adds the same callback into both sides of the processing chain at both points. Keep in mind that the type of the first argument is indeterminate if you use this method! Use it for
finally:style blocks.
Chaining Deferreds
If you need one Deferred to wait on another, all you need to do is return a Deferred from a method added to addCallbacks. Specifically, if you return Deferred B from a method added to Deferred A using A.addCallbacks, Deferred A's processing chain will stop until Deferred B's .callback() method is called; at that point, the next callback in A will be passed the result of the last callback in Deferred B's processing chain at the time.
If this seems confusing, don't worry about it right now -- when you run into a situation where you need this behavior, you will probably recognize it immediately and realize why this happens. If you want to chain deferreds manually, there is also a convenience method to help you.
chainDeferred(otherDeferred)Add
otherDeferredto the end of this Deferred's processing chain. When self.callback is called, the result of my processing chain up to this point will be passed tootherDeferred.callback. Further additions to my callback chain do not affectotherDeferredThis is the same as
self.addCallbacks(otherDeferred.callback, otherDeferred.errback)
See also
- Generating Deferreds, an introduction to writing asynchronous functions that return Deferreds.